

本文通过阿里的Eagleeye(鹰眼)和开源的Skywalking,从数据模型、数据埋点以及数据存储三个方面介绍分布式链路监控系统的实现细节,其中将重点介绍Skywalking字节码增强的实现方案。
背景
随着业务体量的增大,传统的大型单体系统很难满足市场对技术的需求。因此,通过将整个业务系统拆分为多个互相依赖的子系统,并对每个子系统进行独立优化,可以有效提高整个系统的吞吐量。在进行系统拆分之后,完整的业务事务逻辑被分布部署在多个子系统上。用户的一次点击请求将触发多个子系统之间的相互功能调用。链路追踪技术要解决的问题包括如何分析一次用户请求触发的多次跨系统调用过程,以及如何定位存在响应问题的调用链路。
以更专业的方式重新描述该文本: 以网络搜索为例,介绍链路监控系统需要解决的挑战。当用户在搜索引擎中输入关键词时,一个前端服务会将查询分发给数百个查询服务,每个查询服务在自己的索引中执行搜索操作。此外,该查询可能还会被发送给多个子系统,这些子系统可处理敏感词汇、进行拼写检查、用户画像分析或搜索特定领域的结果(如图像、视频、新闻等)。最终,所有这些服务的结果会有选择地合并,并展示在搜索结果页面中,这个过程被称为一次完整的搜索过程。
在进行通用搜索查询时,需要使用数千台机器和多种不同的服务。在网络搜索中,用户的体验和延迟密切相关,搜索延迟可能是由于任何子系统性能不佳造成的。开发人员只关注延迟无法确定整个系统存在的问题,也无法猜测哪个服务或何种行为导致性能问题。首先,开发人员无法准确知道使用了哪些服务,因为随时可能添加新服务或修改现有服务以提升用户体验、性能和安全性等方面的功能。其次,开发人员不可能成为每个内部微服务的专家,因为每个微服务可能由不同团队构建和维护。此外,服务和机器可能与多个客户端共享,导致性能问题可能是由其他应用程序的行为引起的。
Dapper简介
谷歌在2010年发表了一篇论文,介绍了他们内部的分布式链路追踪系统Dapper,并提出了该系统的两个基本要求。首先,该系统需要具有广泛的覆盖范围,即必须能够监控到庞大分布式系统中的每个服务。即使是系统的一小部分没有被监控到,该链路追踪系统也可能是不可靠的。其次,该系统需要提供持续的监控服务,在7*24小时内保障业务系统的健康运行。这可以确保在任何时刻都可以及时发现系统出现的问题,尤其是难以复现的问题。基于这两个基本要求,我们可以确定分布式链路监控系统的设计目标有以下几点:
-
应用级透明
链路监控组件应以通用基础组件的形式向用户提供,以提高稳定性,并使应用开发者不必关注细节。对于Java语言而言,调用方法可以视为最小的操作单位,在实现调用链监控埋点时势必需要对方法进行增强。对于Java语言,方法增强有多种方式可供选择,例如硬编码、动态代理和字节码增强等。应用级透明度实际上是一个相对的概念,高透明度意味着实现难度较大,不同场景可以采用不同的增强方式。
-
低开销
在分布式系统中,低开销是链路监控系统的主要关注点。由于分布式系统对资源和性能的要求非常严格,因此监控组件必须对原服务的影响尽可能小,以最小化对业务主链路的影响。链路监控组件对资源的消耗主要体现在增强方法的消耗上,此外还涉及网络传输和数据存储的消耗。链路监控系统在监控一次请求时会产生额外的数据,并且在请求过程中,这些额外数据不仅会暂时保存在内存中,还会随着请求从上游服务传输至下游服务。因此,在产生额外数据时需要尽量减少数据量,并在网络传输过程中只保留少量必要的数据。
-
扩展性和开放性
无论是何种软件系统,可扩展性和开放性都是衡量其质量优劣的重要标准。对于链路监控系统这样的基础服务系统来说,上游业务系统对于链路监控系统来说是透明的,在一个规模较大的企业中,一个基础服务系统往往会承载成千上万个上游业务系统。每个业务系统由不同的团队和开发人员负责,虽然使用的框架和中间件在同一个企业中有大致的规范和要求,但是在各方面还是存在差异的。因此作为一个基础设施,链路监控系统需要具有非常好的可扩展性,除了对企业中常用中间件和框架的支撑外,还要能够方便开发人员针对特殊的业务场景进行定制化的开发。
数据模型
OpenTracing规范
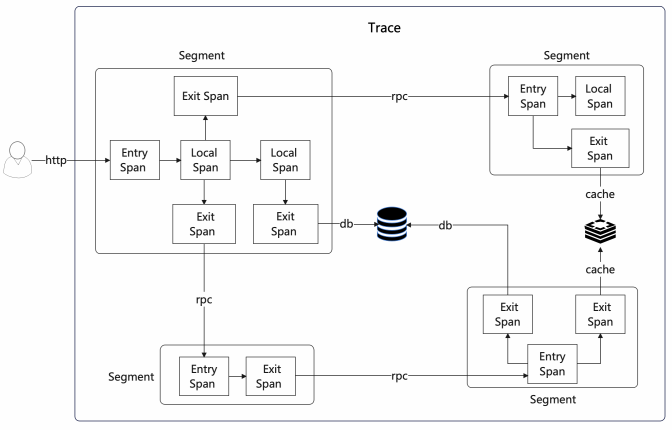
Dapper将请求根据Trace、Segment和Span这三种模型进行划分,该模型已形成OpenTracing规范。OpenTracing用于描述分布式系统中事务的语义,与特定跟踪或监控系统的具体实现无关。因此,对这些事务的描述不应受到任何特定后端数据展示或处理的影响。现在让我们关注一下Trace、Segment和Span这三种模型的具体含义,不再赘述其他大的概念。
-
Trace
表示一整条调用链,包括跨进程、跨线程的所有Segment的集合。
-
Segment
表示一个进程(JVM)或线程内的所有操作的集合,即包含若干个Span。
-
Span
表示一个具体的操作。Span在不同的实现里可能有不同的划分方式,这里介绍一个比较容易理解的定义方式:
1、Entry Span:入栈Span。Segment的入口,一个Segment有且仅有一个Entry Span,比如HTTP或者RPC的入口,或者MQ消费端的入口等。
2、Local Span:通常用于记录一个本地方法的调用。
3、Exit Span:出栈Span。Segment的出口,一个Segment可以有若干个Exit Span,比如HTTP或者RPC的出口,MQ生产端,或者DB、Cache的调用等。
按照上面的模型定义,一次用户请求的调用链路图如下所示:
唯一id
在面对大量请求时,确保每个请求都具有唯一的ID并能包含请求信息是至关重要的。为此,Eagleeye提出了以下traceId设计方案:

基于提供的ID,我们可以推断该请求在2022年10月18日10:10:40被11.15.148.83上的进程号为14031的Nginx服务器接收。在该ID中,有一个四位递增数(从0到9999),用于防止单机并发同时发生traceId碰撞。值得注意的是,此处的标识位为"e"。
关系描述
将请求划分为Trace、Segment、Span三个层次的模型后,如何描述他们之间的关系?
从【OpenTracing规范】一节的调用链路图中可以看出,Trace、Segment可以作为整个调用链路中的逻辑结构,而Span才是真正串联起整个链路的单元,系统可以通过若干个Span串联起整个调用链路。
在Java中,方法是以入栈、出栈的形式进行调用,那么系统在记录Span的时候就可以通过模拟出栈、入栈的动作来记录Span的调用顺序,不难发现最终一个链路中的所有Span呈现树形关系,那么如何描述这棵Span树?Eagleeye中的设计很巧妙,EagleEye设计了RpcId来区别同一个调用链下多个网络调用的顺序和嵌套层次。如下图所示:
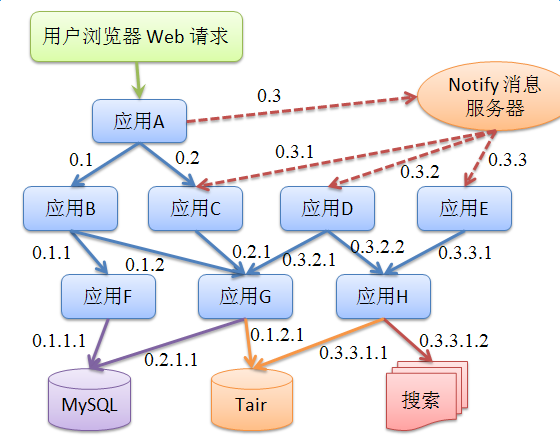
调用链的RpcId标识使用0.X1.X2.X3.....Xi的形式,其中根节点的RpcId从0开始,并且每增加一个"."表示Span在树中的层级增加一层。最后一位数字表示Span在当前层级中的顺序。因此,通过同一个Trace中的所有RpcId,我们可以轻松还原出完整的调用链。
- 0- 0.1- 0.1.1- 0.1.2- 0.1.2.1- 0.2- 0.2.1- 0.3- 0.3.1- 0.3.1.1- 0.3.2
跨进程传输
在整个调用链收集过程中,不可能将整个Trace信息随请求传递到下个应用中。为了减少跨进程传输的Trace信息量,每个应用(Segment)中的数据都是分段收集的。在Eagleeye的实现下,跨Segment的过程只需要携带traceId和rpcid这两个简短的信息即可。在服务端收集数据时,数据也是以分段形式到达。然而,由于多种原因,分段数据可能会出现乱序和丢失的情况。
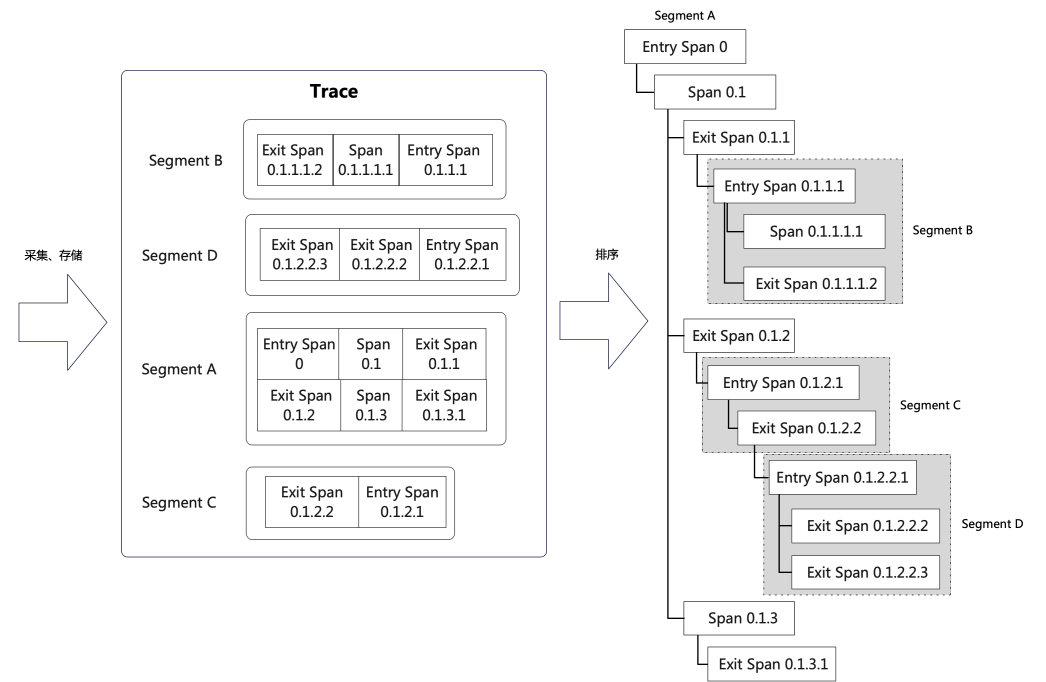
基于图示的收集到的Trace数据,通过rpcid可以还原成一个调用树。当遇到某个Segment数据缺失时,可以使用该节点的第一个子节点来替代。
数据埋点
针对分布式链路追踪系统而言,方法增强(即埋点)的实施是至关重要的。根据Dapper的要求,方法增强需要同时满足透明度和开销两个方面的要求。事实上,应用级透明度是一个相对概念,透明度越高意味着实施难度越大,针对不同的场景,可以采用不同的实现方式。本文拟以阿里的Eagleye和开源的SkyWalking作为案例,对比比较两种方法增强的优缺点。
编码
阿里Eagleye的埋点方式是直接编的码方式,通过中间件预留的扩展点实现。但是按照我们通常的理解来说,编码对于Dapper提出的扩展性和开放性似乎并不友好,那为什Eagleye么要采用这样的方式?个人认为有以下几点:
1、阿里有中间件的使用规范,不是想用什么就用什么,因此对于埋点的覆盖范围是有限的;
2、阿里有给力的中间件团队专门负责中间件的维护,中间件的埋点对于上层应用来说也是应用级透明的,对于埋点的覆盖是全面的;
3、阿里应用有接入Eagleye监控系统的要求,因此对于可插拔的诉求并没有非常强烈。
从上面几点来说,编码方式的埋点完全可以满足Eagleye的需要,并且直接编码的方式在维护、性能消耗方面也是非常有优势的。
字节码增强
相比于Eagleye,SkyWalking这样开源的分布式链路监控系统,在开源环境下就没有这么好做了。开源环境下面临的问题其实和阿里集团内部的环境正好相反:
1、开源环境下每个开发者使用的中间件可能都不一样,想用什么就用什么,因此对于埋点的覆盖范围几乎是无限的;
2、开源环境下,各种中间件都由不同组织或个人进行维护,甚至开发者还可以进行二次开发,不可能说服他们在代码中加入链路监控的埋点;
3、开源环境下,并不一定要接入链路监控体系,大多数个人开发者由于资源有限或其他原因没有接入链路监控系统的需求。
鉴于上述情况,编码方式的埋点无法满足SkyWalking的需求。因此,Skywalking采用以下开发模式:
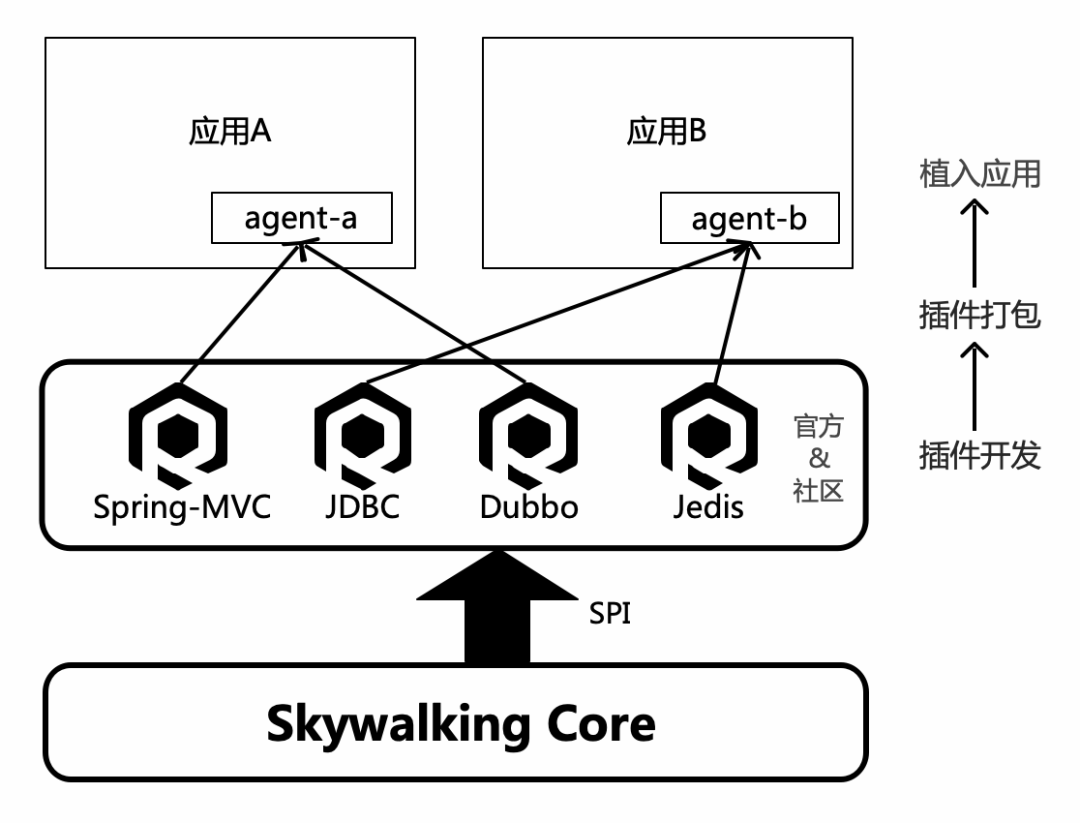
Skywalking是一个提供字节码增强能力和相关扩展接口的技术,用于系统中使用的中间件的埋点。可以使用官方或社区提供的插件来打包中间件,并将其植入到应用程序中。如果没有可用的插件,也可以根据需要开发自定义插件来实现埋点功能。Skywalking利用字节码增强的方法来实现埋点。接下来,将简要介绍字节码增强的相关知识以及Skywalking的实现方式。
两种方式
对Java应用实现字节码增强的方式有Attach和Javaagent两种,本文做一个简单的介绍。
Attach
Attach是一种相对动态的方式,在阿尔萨斯(Arthas)这样的诊断系统中广泛使用,利用JVM提供的Attach API可以实现一个JVM对另一个运行中的JVM的通信。用一个具体的场景举例:我们要实现Attach JVM对一个运行中JVM的监控。如下图所示:
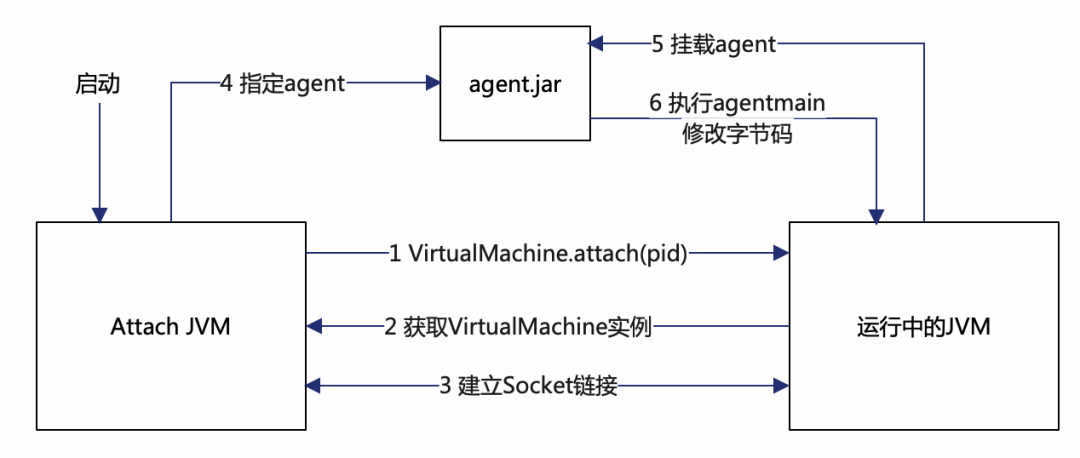
1、Attach JVM利用Attach API获取目标JVM的实例,底层会通过socketFile建立两个JVM间的通信;
2、Attach JVM指定目标JVM需要挂载的agent.jar包,挂载成功后会执行agent包中的agentmain方法,此时就可以对目标JVM中类的字节码进行修改;
3、Attach JVM通过Socket向目标JVM发送命令,目标JVM收到后会进行响应,以达到监控的目的。
尽管Attach工具能够在JVM运行时对字节码进行灵活修改,但是在进行修改时也受到一些限制,如无法增删父类、增加接口、调整字段等。
Javaagent
Javaagent大家应该相对熟悉,他的启动方式是在启动命令中加入javaagent参数,指定需要挂载的agent:
java -javaagent:/path/agent.jar=key1=value1,key2=value2 -jar myJar.jarJavaagent在IDE的调试模式、链路监控系统等场景中被广泛应用。其主要功能是在目标JVM执行main方法之前执行agent的premain方法,从而实现前置逻辑的插入。
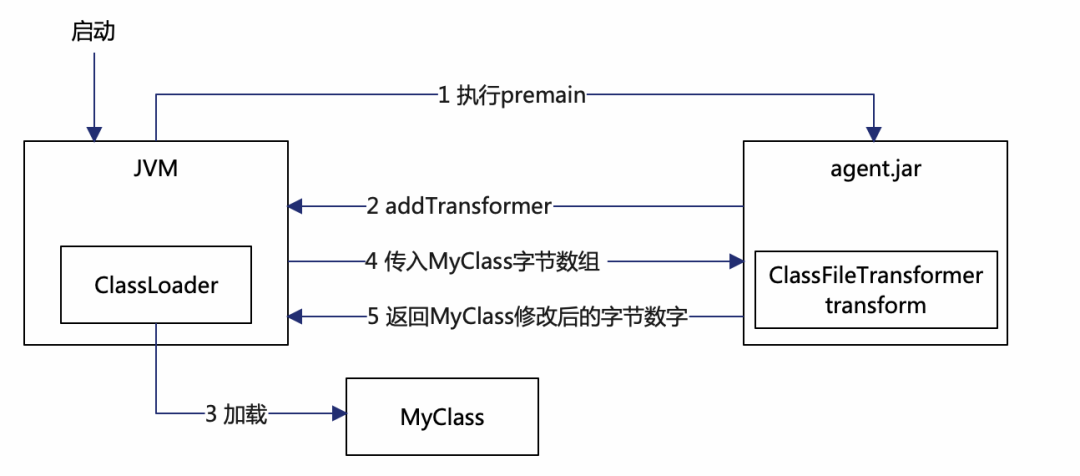
1、目标JVM通过javaagent参数启动后找到指定的agent,执行agent的premain方法;
2、agent中通过JVM暴露的接口添加一个Transformer,顾名思义它可以Transform字节码;
3、目标JVM在类加载的时候会触发JVM内置的事件,回调Transformer以实现字节码的增强。
相比于使用Attach方式,Javaagent只能在main方法执行之前生效。然而,Javaagent具备更大的灵活性,可以修改字节码,甚至能够修改JDK的核心类库。
字节码增强类库
Java提供了多种字节码增强类库,包括cglib、Javassist等广为人知的库,以及Jdk Proxy和ASM等底层库。在2014年,Byte Buddy这款字节码增强类库问世,并在2015年获得了Duke's Choice奖项。Byte Buddy在高性能、易用性和功能强大三个方面都表现出色。以下是从Byte Buddy官方网站摘取的一张常见字节码增强类库性能比较图(单位:纳秒):
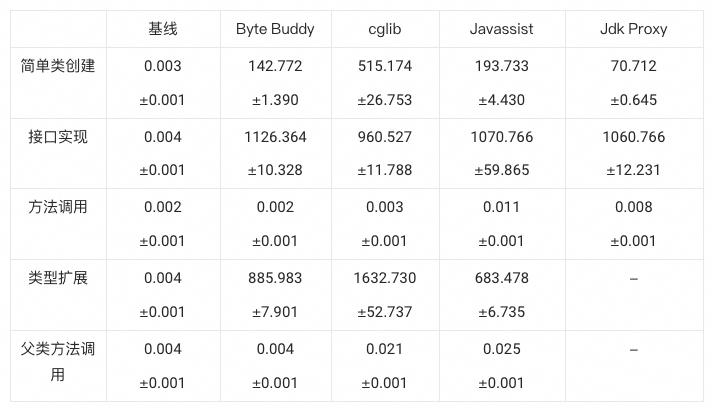
上图中的对比项我们可以大致分为两个方面:生成快速代码(方法调用、父类方法调用)和快速生成代码(简单类创建、接口实现、类型扩展),我们理所应当要优先选择前者。从数据可以看出Byte Buddy在纳秒级的精度下,在方法调用和父类方法调用上和基线基本没有差距,而位于其后的是cglib。
Byte Buddy和cglib有较为出色的性能得益于它们底层都是基于ASM构建,如果将ASM也加入对比那么它的性能一定是最高的。但是用过ASM的同学虽然不一定能感受到它的高性能,但一定能感受到它噩梦般的开发体验:
mv.visitFieldInsn(GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");mv.visitLdcInsn("begin of sayhello().");mv.visitMethodInsn(INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V", false);
Skywalking案例分析
现在我们将结合使用Byte Buddy的案例来体验字节码增强的开发过程。在下面的示例中,我们只会简要介绍相关主要代码,不会涉及细节。
插件模型
Skywalking为开发者提供了简单易用的插件接口,对于开发者来说不需要知道怎么增强方法的字节码,只需要关心以下几点:
-
要增强哪个类的哪个方法?
Skywalking提供了ClassMatch,支持各种类、方法的匹配方式。包括类名、前缀、正则、注解等方式的匹配,除此之外还提供了与、或、非逻辑链接,以支持用户通过各种方式精确定位到一个具体的方法。我们看一个插件中的代码:

我们需要增强字节码中的方法,这些方法没有annotation1注解,并且带有annotation2注解或annotation3注解。我们使用Builder模式提供了ClassMatch,用于以流式编程的方式构建一个内部使用的类匹配逻辑。最终,Skywalking将基于用户提供的ClassMatch实例来执行字节码增强操作。
-
需要添加/修改什么逻辑?
知道了需要增强哪个类的哪个方法,那下一步就是如何增强。Java中的方法可以分为静态方法、实例方法和构造方法三类方法,Skywalking对于这三种方法的增强逻辑为用户提供了不同的扩展点:
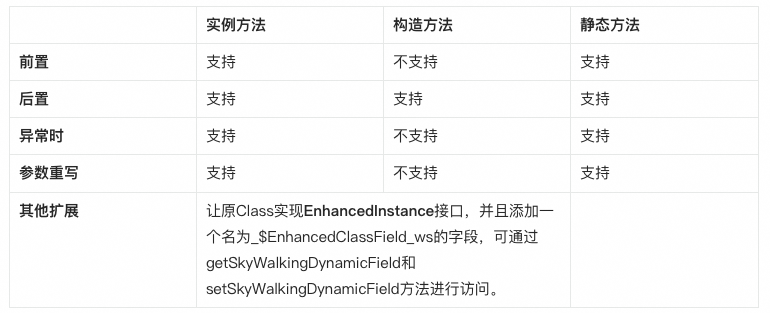
以实例方法为例,Skywalking提供了如下实例方法拦截器:
public interface InstanceMethodsAroundInterceptor {// 方法执行前置扩展点void beforeMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,MethodInterceptResult result) throws Throwable;// 方法执行后置扩展点Object afterMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,Object ret) throws Throwable;// 方法抛出异常时扩展点void handleMethodException(EnhancedInstance objInst, Method method, Object[] allArguments,Class<?>[] argumentsTypes, Throwable t);}
作为IT工程师,我会以更专业的方式重新表达以下内容: 开发人员可以通过实现该接口来对实例方法进行逻辑扩展,实现字节码增强。在方法参数列表中,EnhancedInstance类型的第一个参数实际上表示当前对象(即this指针)。Skywalking中,所有被增强的类的实例方法或构造方法都将实现EnhancedInstance接口。
假设我们有一个Controller,里面只有一个sayHello方法返回"Hello",经过Skywalking增强后,反编译一下它被增强后的字节码文件:

可以看到:
1、Skywalking在其中插入了一个名为_$EnhancedClassField_ws的字段,开发者在某些场合可以合理利用该字段存储一些信息。比如存储Spring MVC中Controller的跟路径,或者Jedis、HttpClient链接中对端信息等。
2、原来的syHello方法名被修改了但仍保存下来,并且新生成了一个增强后的sayHello方法,静态代码块里将经过字节码增强后的sayHello方法存入缓存字段。
增强的前置条件是什么?
在某些时候,并不是只要引入了对应插件就一定会对相关的代码进行字节码增强。比如我们想对Spring MVC的Controller进行埋点,我们使用的是Spring 4.x版本,但是插件却是 5.x 版本的,如果直接对源码进行增强可能会因为版本的差别带来意料之外的问题。Skywalking提供了一种witness机制,简单来说就是当我们的代码中存在指定的类或方式时,当前插件才会进行字节码增强。比如Spring 4.x版本中需要witness这两个类:
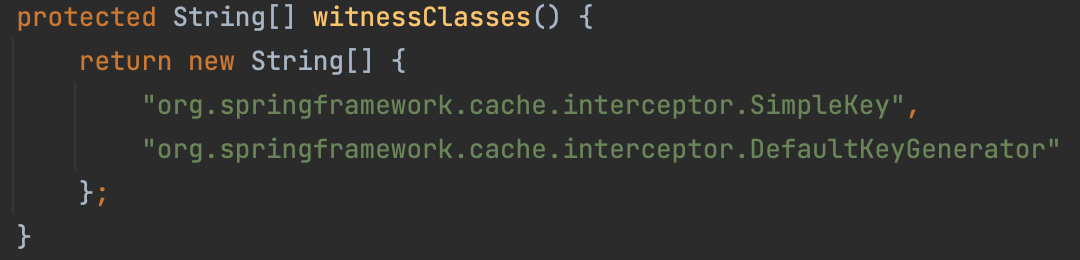
如果粒度不够,还可以对方法进行witness。比如Elastic Search 6.x版本中witness了这个方法:

意思就是SearchHits类中必须有名为getTotalHits、参数列表为空并且返回long的方法。
Skywalking提供了对jdk核心类库的字节码增强的功能,比如对Callable和Runnable类的增强,以支持异步模式下的埋点透传。这涉及到与BootstrapClassLoader的交互。Skywalking在这方面帮助我们处理了复杂的逻辑。下图展示了Skywalking Agent部分整体模型:
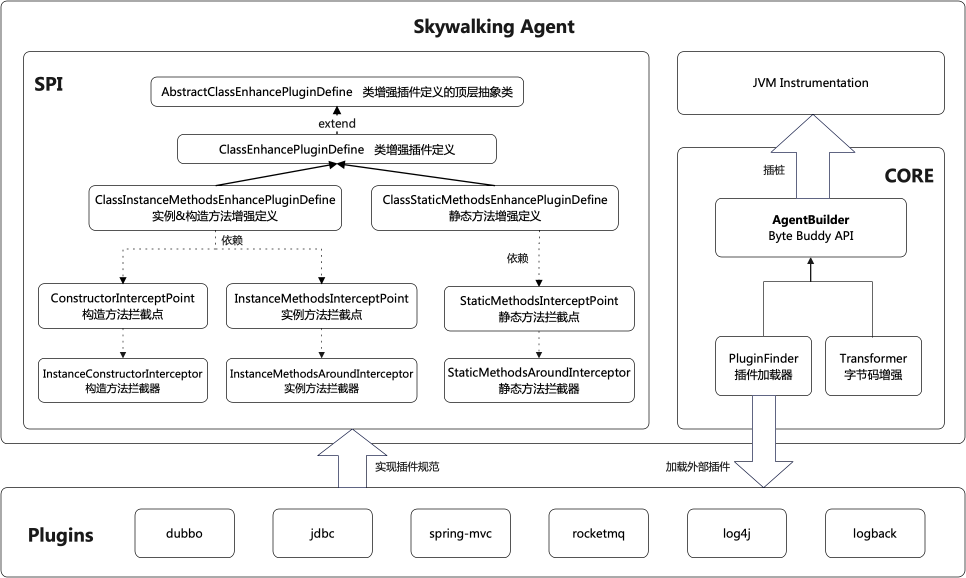
SPI(Service Provider Interface)部分位于Skywalking中,其为开发者提供了一套插件规范接口,开发者可以根据这些接口来实现插件。而Core部分则负责加载这些插件,并利用Byte Buddy提供的字节码增强逻辑,对应用中指定的类和方法的字节码进行增强。
主流程源码
介绍了Skywalking的插件模型后,下面从Javaagent的入口premain开始介绍下主要的流程:
上面的流程主要做了两件事:
1、从指定的目录加载所有插件到内存中;
2、构建Byte Buddy核心的AgentBuilder插桩到JVM的Instrumentation API上,包括需要增强哪些类以及核心的增强逻辑Transformer。
private static class Transformer implements AgentBuilder.Transformer {private PluginFinder pluginFinder;Transformer(PluginFinder pluginFinder) {this.pluginFinder = pluginFinder;}/*** 这个方法在类加载的过程中会由JVM调用(Byte Buddy做了封装)* @param builder 原始类的字节码构建器* @param typeDescription 类描述信息* @param classLoader 这个类的类加载器* @param module jdk9中模块信息* @return 修改后的类的字节码构建器*/@Overridepublic DynamicType.Builder<?> transform(final DynamicType.Builder<?> builder,final TypeDescription typeDescription,final ClassLoader classLoader,final JavaModule module) {LoadedLibraryCollector.registerURLClassLoader(classLoader);// 根据类信息找到针对这个类进行字节码增强的插件,可能有多个List<AbstractClassEnhancePluginDefine> pluginDefines = pluginFinder.find(typeDescription);if (pluginDefines.size() > 0) {DynamicType.Builder<?> newBuilder = builder;EnhanceContext context = new EnhanceContext();for (AbstractClassEnhancePluginDefine define : pluginDefines) {// 调用插件的define方法得到新的字节码DynamicType.Builder<?> possibleNewBuilder = define.define(typeDescription, newBuilder, classLoader, context);if (possibleNewBuilder != null) {newBuilder = possibleNewBuilder;}}// 返回增强后的字节码给JVM,完成字节码增强return newBuilder;}return builder;}}
JVM在类加载时会激发JVM内部事件,并回调Transformer,传递原始类的字节码和类加载器等信息,以实现对字节码的增强。其中,AbstractClassEnhancePluginDefine是插件的一个抽象。
public abstract class AbstractClassEnhancePluginDefine {public DynamicType.Builder<?> define(TypeDescription typeDescription, DynamicType.Builder<?> builder,ClassLoader classLoader, EnhanceContext context) throws PluginException {// witness机制WitnessFinder finder = WitnessFinder.INSTANCE;//通过类加载器找witness类,没有就直接返回,不进行字节码的改造String[] witnessClasses = witnessClasses();if (witnessClasses != null) {for (String witnessClass : witnessClasses) {if (!finder.exist(witnessClass, classLoader)) {return null;}}}//通过类加载器找witness方法,没有就直接返回,不进行字节码的改造List<WitnessMethod> witnessMethods = witnessMethods();if (!CollectionUtil.isEmpty(witnessMethods)) {for (WitnessMethod witnessMethod : witnessMethods) {if (!finder.exist(witnessMethod, classLoader)) {return null;}}}// enhance开始修改字节码DynamicType.Builder<?> newClassBuilder = this.enhance(typeDescription, builder, classLoader, context);// 修改完成,返回新的字节码context.initializationStageCompleted();return newClassBuilder;}protected DynamicType.Builder<?> enhance(TypeDescription typeDescription, DynamicType.Builder<?> newClassBuilder,ClassLoader classLoader, EnhanceContext context) throws PluginException {// 增强静态方法newClassBuilder = this.enhanceClass(typeDescription, newClassBuilder, classLoader);// 增强实例方法& 构造方法newClassBuilder = this.enhanceInstance(typeDescription, newClassBuilder, classLoader, context);return newClassBuilder;}}
通过witness机制检测满足条件后,对静态方法、实例方法和构造方法进行字节码增强。我们以实例方法和构造方法为例:
public abstract class ClassEnhancePluginDefine extends AbstractClassEnhancePluginDefine {protected DynamicType.Builder<?> enhanceInstance(TypeDescription typeDescription,DynamicType.Builder<?> newClassBuilder, ClassLoader classLoader,EnhanceContext context) throws PluginException {// 获取插件定义的构造方法拦截点ConstructorInterceptPointConstructorInterceptPoint[] constructorInterceptPoints = getConstructorsInterceptPoints();// 获取插件定义的实例方法拦截点InstanceMethodsInterceptPointInstanceMethodsInterceptPoint[] instanceMethodsInterceptPoints = getInstanceMethodsInterceptPoints();String enhanceOriginClassName = typeDescription.getTypeName();// 非空校验boolean existedConstructorInterceptPoint = false;if (constructorInterceptPoints != null && constructorInterceptPoints.length > 0) {existedConstructorInterceptPoint = true;}boolean existedMethodsInterceptPoints = false;if (instanceMethodsInterceptPoints != null && instanceMethodsInterceptPoints.length > 0) {existedMethodsInterceptPoints = true;}if (!existedConstructorInterceptPoint && !existedMethodsInterceptPoints) {return newClassBuilder;}// 这里就是之前提到的让类实现EnhancedInstance接口,并添加_$EnhancedClassField_ws字段if (!typeDescription.isAssignableTo(EnhancedInstance.class)) {if (!context.isObjectExtended()) {// Object类型、private volatie修饰符、提供方法进行访问newClassBuilder = newClassBuilder.defineField("_$EnhancedClassField_ws", Object.class, ACC_PRIVATE | ACC_VOLATILE).implement(EnhancedInstance.class).intercept(FieldAccessor.ofField("_$EnhancedClassField_ws"));context.extendObjectCompleted();}}// 构造方法增强if (existedConstructorInterceptPoint) {for (ConstructorInterceptPoint constructorInterceptPoint : constructorInterceptPoints) {// jdk核心类if (isBootstrapInstrumentation()) {newClassBuilder = newClassBuilder.constructor(constructorInterceptPoint.getConstructorMatcher()).intercept(SuperMethodCall.INSTANCE.andThen(MethodDelegation.withDefaultConfiguration().to(BootstrapInstrumentBoost.forInternalDelegateClass(constructorInterceptPoint// 非jdk核心类 .getConstructorInterceptor()))));} else {// 找到对应的构造方法,并通过插件自定义的InstanceConstructorInterceptor进行增强newClassBuilder = newClassBuilder.constructor(constructorInterceptPoint.getConstructorMatcher()).intercept(SuperMethodCall.INSTANCE.andThen(MethodDelegation.withDefaultConfiguration().to(new ConstructorInter(constructorInterceptPoint.getConstructorInterceptor(), classLoader))));}}}// 实例方法增强if (existedMethodsInterceptPoints) {for (InstanceMethodsInterceptPoint instanceMethodsInterceptPoint : instanceMethodsInterceptPoints) {// 找到插件自定义的实例方法拦截器InstanceMethodsAroundInterceptorString interceptor = instanceMethodsInterceptPoint.getMethodsInterceptor();// 这里在插件自定义的匹配条件上加了一个【不为静态方法】的条件ElementMatcher.Junction<MethodDescription> junction = not(isStatic()).and(instanceMethodsInterceptPoint.getMethodsMatcher());// 需要重写入参if (instanceMethodsInterceptPoint.isOverrideArgs()) {// jdk核心类if (isBootstrapInstrumentation()) {newClassBuilder = newClassBuilder.method(junction).intercept(MethodDelegation.withDefaultConfiguration().withBinders(Morph.Binder.install(OverrideCallable.class)).to(BootstrapInstrumentBoost.forInternalDelegateClass(interceptor)));// 非jdk核心类} else {newClassBuilder = newClassBuilder.method(junction).intercept(MethodDelegation.withDefaultConfiguration().withBinders(Morph.Binder.install(OverrideCallable.class)).to(new InstMethodsInterWithOverrideArgs(interceptor, classLoader)));}// 不需要重写入参} else {// jdk核心类if (isBootstrapInstrumentation()) {newClassBuilder = newClassBuilder.method(junction).intercept(MethodDelegation.withDefaultConfiguration().to(BootstrapInstrumentBoost.forInternalDelegateClass(interceptor)));// 非jdk核心类} else {// 找到对应的实例方法,并通过插件自定义的InstanceMethodsAroundInterceptor进行增强newClassBuilder = newClassBuilder.method(junction).intercept(MethodDelegation.withDefaultConfiguration().to(new InstMethodsInter(interceptor, classLoader)));}}}}return newClassBuilder;}}
根据入参是否需要重写和核心类的类型,逻辑会分叉,但大体上的增强逻辑相似。根据用户自定义的插件来定位需要增强的方法和逻辑,并使用Byte Buddy库进行增强操作。
用户通过方法拦截器实现增强逻辑,但是它是面向用户的,并不能直接用来进行字节码增强,Skywalking加了一个中间层来连接用户逻辑和Byte Buddy类库。上述代码中的XXXInter便是中间层,比如针对实例方法的InstMethodsInter:
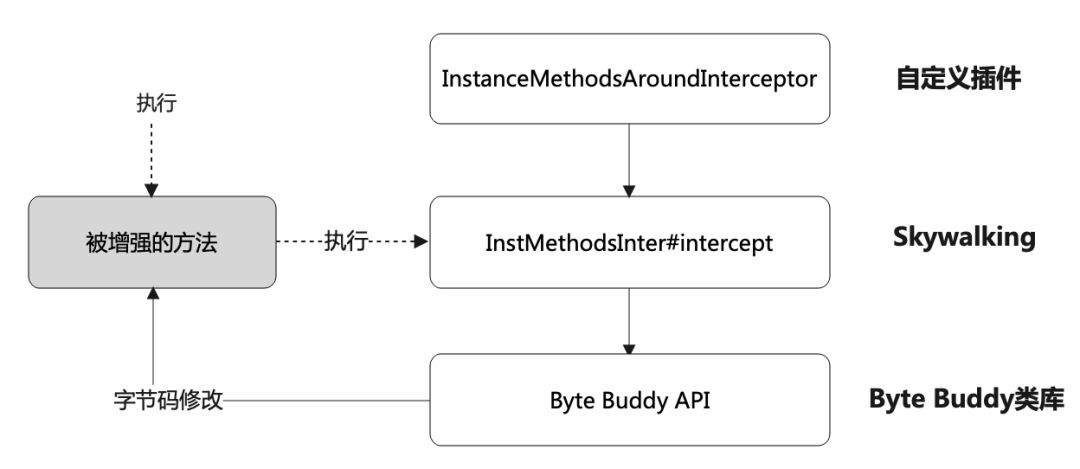
InstMethodsInter用于封装用户自定义逻辑,并与ByteBuddy的核心类库进行接口连接。当执行被字节码增强的方法时,会调用InstMethodsInter的intercept方法。我们可以通过将被增强后的类的字节码文件与之进行反编译并进行对比,以验证此过程。
public class InstMethodsInter {private static final ILog LOGGER = LogManager.getLogger(InstMethodsInter.class);// 用户在插件中定义的实例方法拦截器private InstanceMethodsAroundInterceptor interceptor;public InstMethodsInter(String instanceMethodsAroundInterceptorClassName, ClassLoader classLoader) {try {// 加载用户在插件中定义的实例方法拦截器interceptor = InterceptorInstanceLoader.load(instanceMethodsAroundInterceptorClassName, classLoader);} catch (Throwable t) {throw new PluginException("Can't create InstanceMethodsAroundInterceptor.", t);}}/*** 当执行被增强方法时,会执行该intercept方法** @param obj 实例对象(this)* @param allArguments 方法入参* @param method 参数描述* @param zuper 原方法调用的句柄* @param method 被增强后的方法的引用* @return 方法返回值*/@RuntimeTypepublic Object intercept(@This Object obj, @AllArguments Object[] allArguments, @SuperCall Callable<?> zuper,@Origin Method method) throws Throwable {EnhancedInstance targetObject = (EnhancedInstance) obj;MethodInterceptResult result = new MethodInterceptResult();try {// 拦截器前置逻辑interceptor.beforeMethod(targetObject, method, allArguments, method.getParameterTypes(), result);} catch (Throwable t) {LOGGER.error(t, "class[{}] before method[{}] intercept failure", obj.getClass(), method.getName());}Object ret = null;try {// 是否中断方法执行if (!result.isContinue()) {ret = result._ret();} else {// 执行原方法ret = zuper.call();// 为什么不能走method.invoke?因为method已经是被增强后方法,调用就死循环了!// 可以回到之前的字节码文件查看原因,看一下该intercept执行的时机}} catch (Throwable t) {try {// 拦截器异常时逻辑interceptor.handleMethodException(targetObject, method, allArguments, method.getParameterTypes(), t);} catch (Throwable t2) {LOGGER.error(t2, "class[{}] handle method[{}] exception failure", obj.getClass(), method.getName());}throw t;} finally {try {// 拦截器后置逻辑ret = interceptor.afterMethod(targetObject, method, allArguments, method.getParameterTypes(), ret);} catch (Throwable t) {LOGGER.error(t, "class[{}] after method[{}] intercept failure", obj.getClass(), method.getName());}}return ret;}}
上述逻辑其实就是下图中红框中的逻辑:

Byte Buddy提供了声明式方式,通过几个注解就可以实现字节码增强逻辑。
数据收集
接下来的操作是将收集到的追踪数据发送到服务器。为了最小化对主链路的影响,通常会选择先将数据存储在本地,然后再异步进行采集。Skywalking和Eagleeye在实现上有一些不同之处,我们将分别进行介绍。
存储
Eagleeye
鹰眼采用并发环形队列存储Trace数据,如下图所示:
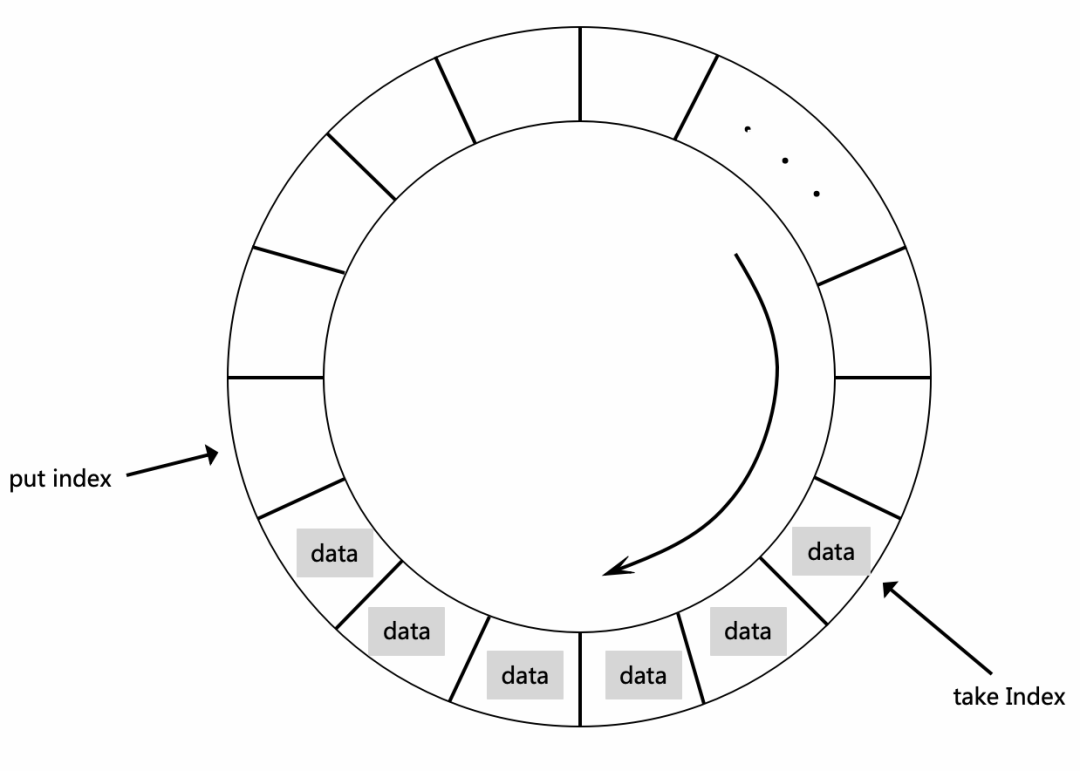
环形队列广泛应用于许多日志框架的异步写入过程。其基本结构包括读指针(take),用于指示队列中最后一条数据的位置;写指针(put),用于指示下一个数据存放的位置。这种队列支持原子读取和写入操作。take和put指针在时钟方向上移动,当数据生产速度超过消费速度时,put指针可能“追上”take指针(即形成一个环),此时可以根据不同的策略选择丢弃即将写入的数据或覆盖较旧的数据。
Skywalking
Skywalking在实现上有所区别,采用分区的QueueBuffer存储Trace数据,多个消费线程通过Driver平均分配到各个QueueBuffer上进行数据消费:
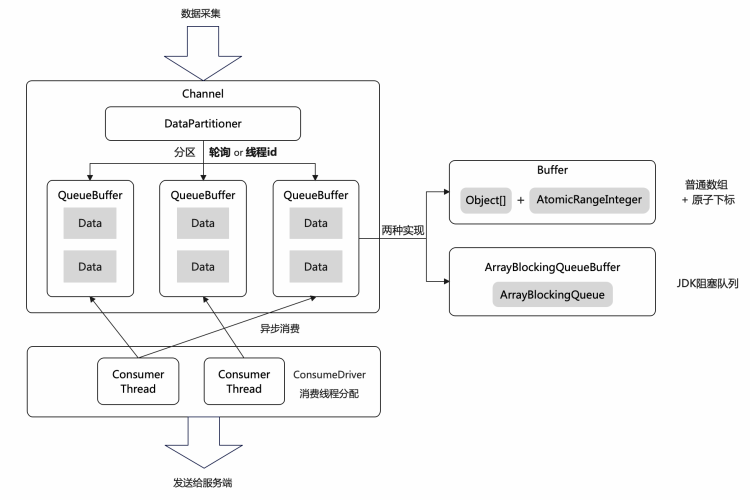
QueueBuffer有两种实现方式:一种是基于JDK的阻塞队列,另一种是使用普通数组和原子下标。Skywalking根据不同的使用场景选择不同的实现方式:在服务端,使用基于JDK的阻塞队列,而在Agent端,使用普通数组和原子下标的方式。后者更轻量且性能更高。接下来,将介绍后者的一些有趣之处。
有趣的原子下标
普通的Oject数组是无法支持并发的,但只要保证每个线程获取下标的过程是原子的,即可保证数组的线程安全。这需要保证:
1、多线程获取的下标是依次递增的,从0开始到数组容量-1;
2、当某个线程获取的下标超过数组容量,需要从0开始重新获取。
这其实并不难实现,通过一个原子数和取模操作一行代码就能完成上面的两个功能。但我们看Skywalking是如何实现这个功能的:
// 提供原子下标的类public class AtomicRangeInteger {// JDK提供的原子数组private AtomicIntegerArray values;// 固定值15private static final int VALUE_OFFSET = 15;// 数组开始下标,固定为0private int startValue;// 数组最后一个元素的下标,固定为数组的最大长度-1private int endValue;public AtomicRangeInteger(int startValue, int maxValue) {// 创建一个长度为31的原子数组this.values = new AtomicIntegerArray(31);// 将第15位设置为初始值0this.values.set(VALUE_OFFSET, startValue);this.startValue = startValue;this.endValue = maxValue - 1;}// 核心方法,获取数组的下一个下标public final int getAndIncrement() {int next;do {// 原子递增next = this.values.incrementAndGet(VALUE_OFFSET);// 如果超过了数组范围,CAS重制到0if (next > endValue && this.values.compareAndSet(VALUE_OFFSET, next, startValue)) {return endValue;}} while (next > endValue);return next - 1;}}
Skywalking使用JDK的原子数组来进行相关的原子操作,其中固定的第15位是一个长度为31的数组。在JDK8中,原子数组利用Unsafe通过偏移量直接对数组中的元素进行内存操作。为何要采用这种方法呢?我们将这称为V1版本。接下来我们来看一下V2版本,这是Skywalking早期版本使用的代码。
public class AtomicRangeInteger {private AtomicInteger value;private int startValue;private int endValue;public AtomicRangeInteger(int startValue, int maxValue) {this.value = new AtomicInteger(startValue);this.startValue = startValue;this.endValue = maxValue - 1;}public final int getAndIncrement() {int current;int next;do {// 获取当前下标current = this.value.get();// 如果超过最大范围则从0开始next = current >= this.endValue ? this.startValue : current + 1;// CAS更新下标,失败则循环重试} while (!this.value.compareAndSet(current, next));return current;}}
对比V1版本,人眼可以观察到V2版本的代码逻辑较差。这是因为在V2中,获取当前值和CAS更新这两个步骤是分开进行的,缺乏原子性。因此,V2版本存在更高的并发冲突风险,从而导致循环次数增加。相比之下,使用JDK提供的incrementAndGet方法可提高效率。接下来,我们来看一下V3版本:
public class AtomicRangeInteger extends Number implements Serializable {// 用原子整型替代V1版本的原子数组private AtomicInteger value;private int startValue;private int endValue;public AtomicRangeInteger(int startValue, int maxValue) {this.value = new AtomicInteger(startValue);this.startValue = startValue;this.endValue = maxValue - 1;}public final int getAndIncrement() {int next;do {next = this.value.incrementAndGet();if (next > endValue && this.value.compareAndSet(next, startValue)) {return endValue;}}while (next > endValue);return next - 1;}}
通过更改代码中的第15位的AtomicIntegerArray为AtomicInteger,实现了更专业的版本。此外,还有一个非常简单的V4版本,通过一个原子数和取模操作完成程序的功能。
public class AtomicRangeInteger {private AtomicLong value;private int mask;public AtomicRangeInteger(int startValue, int maxValue) {this.value = new AtomicLong(startValue);this.mask = maxValue - 1;}public final int getAndIncrement() {return (int)(value.incrementAndGet() % mask);}}
通过Benchmark压测数据来看看这几个版本的性能有什么差别,固定128线程,3轮预热、5轮正式,每轮10s。
-
Skywalking官方数据(数组大小100):
| 版本 | 得分 | 描述 |
| V1 | 45832615.061 ± 2987464.163 ops/s | 原子数组第15位操作 |
| V2 | 13496720.554 ± 240134.803 ops/s | 老版本 |
| V3 | 39201251.850 ± 1005866.969 ops/s | 原子整数代替原子数组第15位 |
-
自己在mac上测试的数据(数组大小100):
| 版本 | 得分 | 描述 |
| V1 | 37368086.272 ± 2702764.084 ops/s | 原子数组第15位操作 |
| V2 | 8066661.954 ± 1165851.129 ops/s | 老版本 |
| V3 | 26124150.437 ± 684039.516 ops/s | 原子整数代替原子数组第15位 |
| V4 | 51063216.834 ± 7775168.064 ops/s | 原子数取模 |
-
自己在mac上测试的数据(数组大小128):
| 版本 | 得分 | 描述 |
| V1 | 29452469.035 ± 1853738.513 ops/s | 原子数组第15位操作 |
| V2 | 7998178.059 ± 148894.535 ops/s | 老版本 |
| V3 | 39011356.081 ± 3603737.004 ops/s | 原子整数代替原子数组第15位 |
| V4 | 61012525.493 ± 6054137.447 ops/s | 原子数取模 |
根据Skywalking官方发布的测试结果显示,V1版本在通过原子数组的固定第15位操作方案下表现最佳。然而,在我个人进行本机环境测试时,发现V3版本在通过原子整数代替的方式下,其性能与V1版本相比表现不稳定;而在使用原子数取模的方案下,性能最高。个人推测,Skywalking可能通过原子数组的固定第15位操作来进行缓存填充,但测试结果很大程度上受环境影响。而不采用原子数取模的原因可能是因为原子数会无限递增,导致性能下降。
传输
最后一步就是数据的传输,如下图所示:
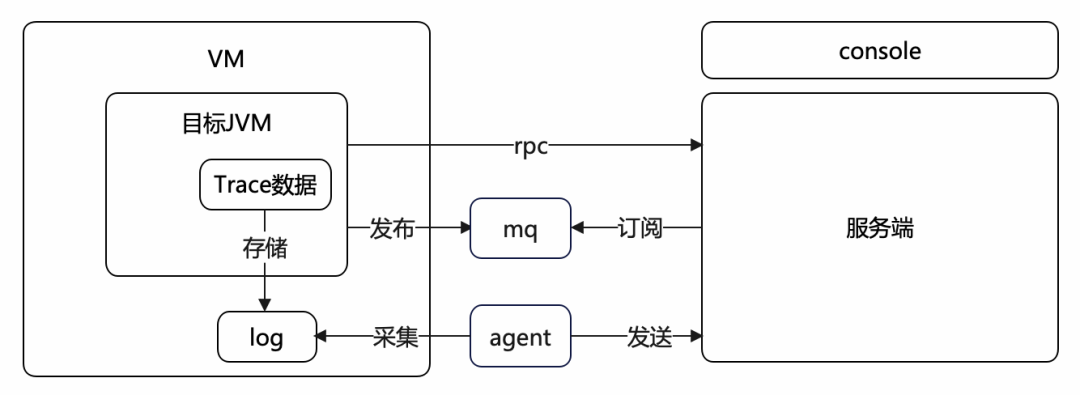
Skywalking被设计为支持GRPC和Kafka两种数据传输方式。相比之下,鹰眼先将数据存储在本地日志中,然后通过代理程序将数据采集到服务器。与Skywalking相比,用户可以直接在计算机上查看追踪日志,而Skywalking则提供了一个日志插件,以提供可插拔的本地追踪存储功能。
从整体上来看,Skywalking采取了埋点和中间件代码分离的方式,在某种意义上实现了应用级透明,但是在后期维护的过程中中间件版本的升级需要配合插件版本的升级,在维护方面带来了一些问题。而Eagleeye编码方式的埋点由中间件团队维护,对于上层的应用也是透明的,更加适合阿里集团内部的环境。
